Ефективне використання Cursor та оптимізація витрат на AI
Cursor значно прискорює розробку, але неправильне використання може швидко вичерпати AI-ліміти. Цей документ описує кращі практики для розробників, щоб ефективно використовувати AI без втрати якості коду. Без дотримання рекомендацій ліміт $10 може бути використаний за 1–3 дні. При правильному використанні той самий ліміт може вистачити на весь місяць.
AI
Ефективне використання Cursor та оптимізація витрат на AI
Cursor значно прискорює розробку, але неправильне використання може швидко вичерпати AI-ліміти.
Цей документ описує кращі практики для розробників, щоб ефективно використовувати AI без втрати якості коду.
Без дотримання рекомендацій ліміт $10 може бути використаний за 1–3 дні.
При правильному використанні той самий ліміт може вистачити на весь місяць.
Основні принципи
1. Використовуйте правильну модель для задачі
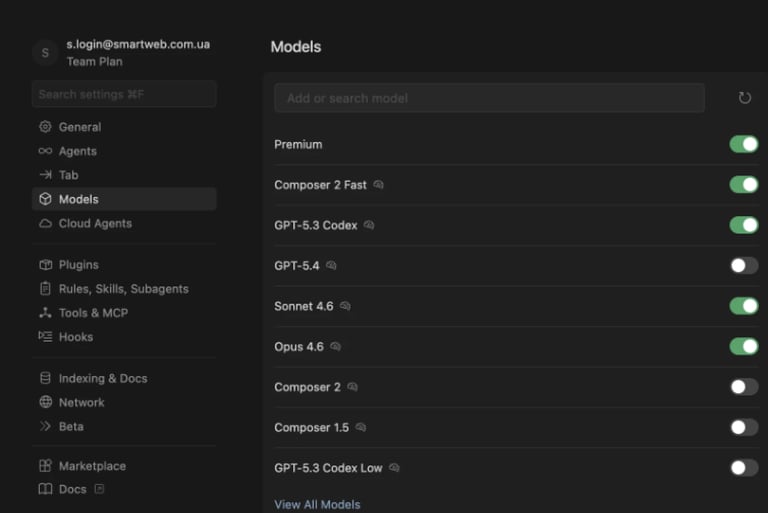
Не кожна задача потребує найпотужнішої AI-моделі.

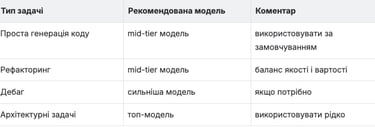
Правило:
80–90% задач не потребують найдорогішої моделі.
Кращі практики:
Default: Sonnet / GPT-4.1
Heavy tasks: Opus - ! НЕ РОБИТИ ЇЇ ДЕФОЛТНОЮ, тільки для дуже важких задач.
2. Обмежуйте контекст
Один із найбільших факторів витрат зайвий контекст. Так багато думає чим більше контекста тим якісніша відповідь, але тут треба балансувати над тим де іде зайвий контекст, який навіть не відноситься до рішення даної задачі, а при дефолті надають все - що здорожчує рішення
Не потрібно надсилати весь репозиторій або великі непотрібні файли.
Поганий приклад
Explain how our entire payment system works.
Кращий приклад
@payment.service.ts
Explain retry logic in this service.
Рекомендації
використовувати @file (давайте розкажу нижче що це таке)
додавати лише релевантні файли
не надсилати весь repo без потреби
2.1 Що робить @file у Cursor
Коли ви пишете:
@payment.service.ts
ви явно говорите Cursor:
Використай цей файл як контекст для відповіді.
Cursor бере:
повний текст файлу
додає його в prompt
модель використовує цей код для аналізу.
Тобто фактично формується prompt типу:
SYSTEM PROMPT
User prompt
FILE CONTENT:
payment.service.ts
...
Для чого це потрібно
1) Щоб модель працювала з правильним контекстом та контроль токенів
Без @file модель часто не знає про який код іде мова.
Модель не бачить код.
Cursor може:
підтягнути випадкові файли, для прикладу піти так
payment.service.ts
payment.client.ts
payment.types.ts
logger.ts
retry.util.ts
≈ 6k–12k токенів контексту замість ≈ 1k–3k токенівабо взагалі здогадуватись.
2) Менше hallucinations
Коли контекст нечіткий, модель починає:
вигадувати функції
вигадувати API
придумувати архітектуру
Наприклад: Без @file
Модель може написати: paymentClient.retry() якого у проекті не існує.
Наприклад: З @file
Модель може написати: this.paymentClient.charge() і працює з реальним кодом.
3)Точніший refactoring
Refactoring без контексту майже завжди поганий.
Без @file
Refactor this logic
Модель не знає:
типи
імпорти
залежності
З @file
@payment.service.ts
Refactor retry logic
Модель бачить:
типи
функції
імпорти
залежності
4) Менше переписування файлів
Якщо не використовувати @file, Cursor часто:
генерує новий файл
переписує код
втрачає структуру
А з @file модель працює відносно існуючого коду.
Коли використовувати @file
Завжди коли:
дебаг
рефакторинг
аналіз коду
додавання тестів
зміни логіки
Коли НЕ потрібно
Якщо питання загальне:
Explain dependency injection in NestJS
тут @file не потрібен.
Золоте правило для devs
Хороший prompt майже завжди виглядає так:
@file
Task
Constraints
Приклад:
@user.service.ts
Add validation for email before saving user.
Constraints:
minimal diff
keep existing API
return code only
3. Просіть мінімальні зміни в коді
AI часто переписує весь файл, навіть якщо потрібно змінити лише кілька рядків.
Поганий prompt
Rewrite this file with improvements.
Кращий prompt
Refactor only this function.
Return minimal diff.
Це значно зменшує кількість токенів.
4. Уникайте довгих пояснень
Пояснення сильно збільшують кількість токенів у відповіді.
Поганий prompt
Explain all your changes in detail.
Кращий prompt
Return code only.
No explanation.
Пояснення варто використовувати лише коли потрібно розібратися з логікою або архітектурою.
5. Не використовуйте Regenerate часто
Кожне натискання Regenerate — це новий AI-запит.
Приклад:


Краще уточнювати попередню відповідь:
Adjust the previous answer to include tests.
6. Об’єднуйте задачі
Кілька маленьких запитів часто дорожчі, ніж один структурований.
Неефективний сценарій
Write function
Rewrite function
Optimize function
Add tests
Explain changes
Кращий сценарій
Write function including edge cases and tests.
7. Rules (найважливіше)
Правильні правила зменшують витрати токенів і відповіді працюють стабільнішими а не кожен раз нова відповідь
Rules застосовуються лише до Agent / AI interactions, а не до:
autocomplete
inline suggestions
Тобто вони впливають на:
Chat
Agent
AI commands
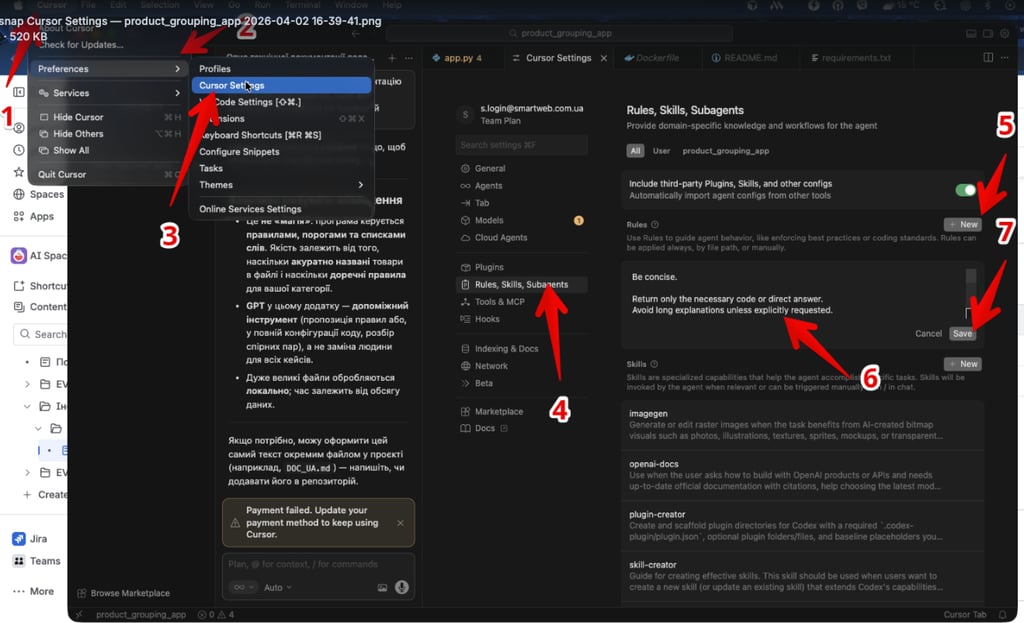
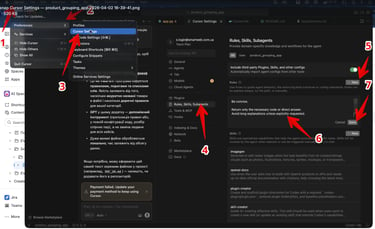
Cursor IDE → Settings → Rules, Skills, Subagents → User →New User Rule
і додай правило типу:
Be concise.
Return only necessary code or direct answers.
Avoid long explanations unless explicitly requested.
When modifying code:
change only the relevant lines
do not rewrite entire files
prefer minimal diffs
Focus only on provided context.
Як вони комбінуються
Коли dev робить AI запит, Cursor фактично збирає prompt так:
User Rules+Prompt+Context (@file)
8. Indexing & Docs (дуже впливає на токени)
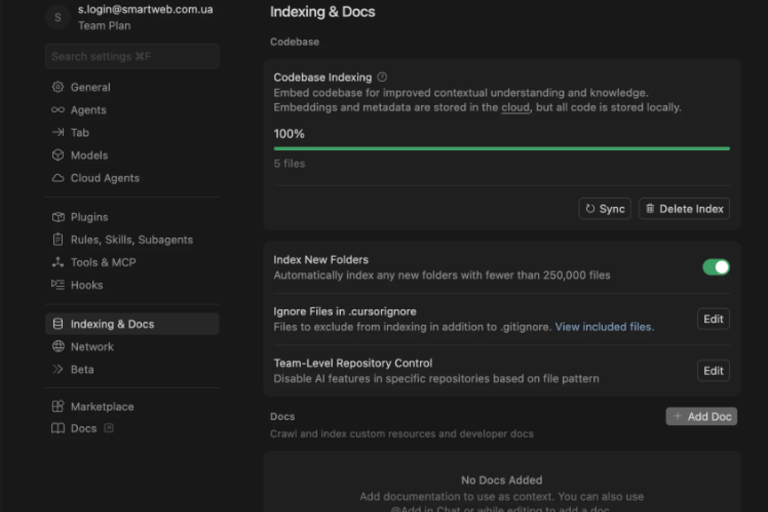
Там Cursor будує індекс repo. В розділі codebase indexing відображається який відсоток індексів побудований для ваших репо з якимии ви працюєте, чим більше відсоток тим менше надалі токенів потрібно для виконання задач.
Виключити великі папки Ignore Files in .cursorignore
Типові папки які треба виключити:
node_modules
dist
build
coverage
.next
.cache
.venv
venv
pycache
*.log
*.lock
Якщо цього не зробити Cursor може:
індексувати десятки тисяч файлів
підтягувати непотрібний контекст
витрачати зайві токени
У великих repo це одна з головних причин великих запитів.
Team-Level Repository Control
Тут можна взагалі вимкнути AI для деяких repo.
Наприклад:
/infra/
/terraform/
/vendor/
9. Кожну нову задачу починайте з нового чата
Так як нова задача може бути взагалі не повʼязана з минулосю задачею а в станому чаті зберігається повна інформація про старий контекст, то це може призводити до великого використання токенів, так як буде оброблюватись контекст з старої задачі.
Підсумуємо, найбільша економія токенів відбувається в Шести звичках dev-ів.
1. Використовувати @file
2. Просити minimal diff
3. Не натискати regenerate
4. Обмежити індексацію до репо або файлів які не потрібні
5. Прописати Рулси для промта
6. Здоровий глузд при використані моделі до задач
Приклад З та Без рекомендацій в токенах на реальній своїй задачці з підрахунку часу на розробку місій
Задача
додати retry logic у неуспішне отримання відповіді при отримані задачі jira
обробити timeout
провести підрахунок відсотку від нарахованих годин з Jira
У проекті є:
distribute_month_rows_minibudgets.py — ~350 рядків
monthly_check.py — ~660 рядків
build_filtered_ceo_summary.py — ~200 рядків
build_ceo_summary_and_upload_vchasno_ — ~320 рядків
Сценарій A — без рекомендацій
Типовий prompt
Please analyze our Jira hour calculation flow and add retry logic for failed task fetching.
Also handle timeout errors and calculate percentage from accrued Jira hours.
Improve the code if needed and explain all your changes.
Що зазвичай стається далі:
Cursor сам підтягне кілька файлів
може взяти майже всі 4 файли, бо задача схожа на cross-file logic
підтягне історію чату
модель дасть пояснення
часто перепише великі шматки коду
dev ще натисне 1–2 Regenerate
Оцінка контексту
Грубо по обсягу:
distribute_month_rows_minibudgets.py — 350 рядків
monthly_check.py — 660 рядків
build_filtered_ceo_summary.py — 200 рядків
build_ceo_summary_and_upload_vchasno_ — 320 рядків
Разом: ~1530 рядків коду
Для Python це легко може бути приблизно:
20 000 input токенів, якщо Cursor підтягне всі 4 файли + службовий контекст + історію
Чому так багато:
код
системні інструкції
repo/index context
prompt
історія
іноді частини попередніх відповідей
Оцінка output
Якщо prompt розмитий і є фрази:
“analyze flow”
“improve code quality”
“explain all changes”
то модель часто повертає:
пояснення: 1 800 токенів
код змін: 2 000 токенів
можливий перепис великих фрагментів: ще 2 000 токенів
Разом output:
5 800 токенів
Разом за 1 запит без практик
Орієнтовно:
input: 20 000
output: 5 800
Разом:
25 800 токенів за один запит
Якщо було 2 regenerate
Тоді загалом по задачі:
77 000 токенів
І це ще без сильного роздуття історії чату. У реальному житті може бути й більше, якщо модель кожного разу читає попередню невдалу відповідь і нові уточнення.
Сценарій 2 — з практиками економії
Тепер беремо ту саму задачу, але працюємо правильно.
1. Даємо тільки релевантні файли
Наприклад, якщо основна логіка Jira fetch і підрахунок сидить у двох файлах, то не треба одразу кидати всі чотири.
Приклад prompt:
@monthly_check.py
@distribute_month_rows_minibudgets.py
Add retry logic for failed Jira task fetching.
Handle timeout errors.
Add calculation of percentage from accrued Jira hours.
Constraints:
do not change public behavior outside this logic
return minimal diff only
no explanation
2. Є Team Rules
be concise
minimal diff
no long explanations
focus only on provided context
3. Використовується не Opus, а mid / balanced model
Наприклад Sonnet або інша хороша робоча модель.
Оцінка input
Якщо беремо лише 2 файли:
monthly_check.py — 660 рядків
distribute_month_rows_minibudgets.py — 350 рядків
Разом: ~1010 рядків
Це вже орієнтовно:
10 000 input токенів
Якщо prompt короткий, історія невелика, і Cursor не тягне зайве.
Якщо ще краще іти частинами, наприклад спочатку тільки Jira fetch logic, тоді можна знизити ще нижче:
7 000 input токенів
Оцінка output
Бо ми просимо:
minimal diff
no explanation
тільки потрібні зміни
То output часто буде:
зміни в логіці retry/timeout: 700 токенів
формула/обчислення відсотка: 300 токенів
невеликий diff по кількох місцях: 500 токенів
Разом:
1 500 токенів
Разом за 1 запит з практиками
Орієнтовно:
input: 10 000
output: 1 500
Разом:
11 500 токенів
Реальна економія
Було: 77k
Стало: 11.5k
Економія:
приблизно у 6 разів !
Де проходить межа “економія без втрати якості”
Економити треба не на мисленні моделі, а на смітті навколо задачі.
Тобто якість не падає, якщо:
залишити правильну модель для правильного типу задач
дати релевантний контекст
попросити короткий і точний результат
Якість починає падати, коли:
занадто слабка модель використовується для реально важкої задачі
контекст обрізаний настільки, що модель не бачить важливих залежностей
prompt занадто короткий і не містить обмежень